I’ve been looking to go back and practice some of the basics of R programming. “Quantitative Politics with R” by Erik Gahner Larsen and Zoltán Fazekas has a chapter on creating data through some simple web scraping and that’s what I’ll be using for this practice.
Create data by webscraping online files
Let’s begin by testing a single election file from 1955 and inspecting the data to verify it’s what we want.
el_1955 <- read_delim(
"https://www.electoralcalculus.co.uk/electdata_1955.txt",
delim = ";"
) # Import file from url
## Rows: 630 Columns: 11
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ";"
## chr (3): Name, MP, County
## dbl (8): Area, Electorate, CON, LAB, LIB, NAT, MIN, OTH
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
head(el_1955) # View first 6 rows
## # A tibble: 6 × 11
## Name MP Area County Electorate CON LAB LIB NAT MIN OTH
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Abingdon AMS … 12 Berks… 58487 25613 16979 8634 0 0 0
## 2 Accrington H Hy… 4 Lanca… 50938 21157 22502 0 0 0 0
## 3 Acton JA S… 11 Ealing 49373 20120 20645 0 0 0 0
## 4 Aldershot E Er… 12 Hamps… 54209 22701 13129 4232 0 0 0
## 5 Altrincham … FJ E… 4 Centr… 61525 30586 12174 6436 0 0 0
## 6 Arundel and… HB K… 12 West … 69034 35180 15188 0 0 0 0
We can see that the above data loaded correctly, so now we can set up a function to scrape the files for the election years we are interested in.
First, we’ll make a list of the election years we’d like to collect data from.
election_years <- c("1955", "1959", "1964", "1966", "1970", "1974feb",
"1974oct", "1979", "1983", "1987", "1992ob", "1997",
"2001ob", "2005ob", "2010", "2015", "2017")
Next we’ll put together a function to scrape data. From our test link we can see that the year and file type are at the end of the url. So, we’ll use past0() to concatenate our url with the year and file type. Then we’ll use read_delim() as we did previously to import the data. Finally, we’ll use the mutate function to add a ‘year’ column and use the election year to fill the column for each dataset.
read_election_data <- function(election) {
url <- paste0("http://www.electoralcalculus.co.uk/electdata_",
election, ".txt")
read_delim(url, delim = ";") %>%
mutate(year = election)
}
Now that we’ve created the function, we can use lapply() to run the function across the list of years we previously specified, and bind_rows() to put all of the data together into one dataframe. Then we’ll inspect the results.
elections <- bind_rows(lapply(election_years, read_election_data))
head(elections)
## # A tibble: 6 × 14
## Name MP Area County Electorate CON LAB LIB NAT MIN OTH year
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 Abing… AMS … 12 Berks… 58487 25613 16979 8634 0 0 0 1955
## 2 Accri… H Hy… 4 Lanca… 50938 21157 22502 0 0 0 0 1955
## 3 Acton JA S… 11 Ealing 49373 20120 20645 0 0 0 0 1955
## 4 Alder… E Er… 12 Hamps… 54209 22701 13129 4232 0 0 0 1955
## 5 Altri… FJ E… 4 Centr… 61525 30586 12174 6436 0 0 0 1955
## 6 Arund… HB K… 12 West … 69034 35180 15188 0 0 0 0 1955
## # ℹ 2 more variables: UKIP <dbl>, Green <dbl>
Create data by webscraping online tables
Next we’ll practice scraping data from tables found on a webpage.
First, specify the link and save it as an object.
url <- c(
"https://en.wikipedia.org/wiki/2014_European_Parliament_election_in_the_United_Kingdom"
)
Then, using read_html, we’ll save the data from the page.
wikipage <- read_html(url)
Then take a look at the class of data we saved.
class(wikipage)
## [1] "xml_document" "xml_node"
We can see that we saved an xml_document and xml_node. Next we’ll want to save the tables found on the with page data and look at what we’ve got.
data_table <- html_elements(wikipage,"table") # Specify we're looking for all "table" elements.
data_table
## {xml_nodeset (25)}
## [1] <table class="infobox vevent" style="line-height: 1.5em; width:500px">\n ...
## [2] <table style="width:100%; margin:1px; display:inline-table;"><tbody><tr> ...
## [3] <table style="background:transparent; width:100%;"><tbody>\n<tr style="d ...
## [4] <table cellspacing="0" cellpadding="0" style="background:transparent; wi ...
## [5] <table class="sidebar sidebar-collapse nomobile vcard"><tbody>\n<tr><td ...
## [6] <table style="width:100%;border-collapse:collapse;border-spacing:0px 0px ...
## [7] <table style="width:100%;border-collapse:collapse;border-spacing:0px 0px ...
## [8] <table class="wikitable sortable">\n<caption>Representation by region\n< ...
## [9] <table class="wikitable" style="font-size:90%"><tbody>\n<tr><th colspan= ...
## [10] <table class="wikitable sortable" style="text-align:center; font-size:90 ...
## [11] <table class="wikitable sortable" style="text-align:center; font-size:90 ...
## [12] <table class="wikitable sortable" style="text-align:center; font-size:90 ...
## [13] <table class="wikitable sortable" style="text-align:center; font-size:90 ...
## [14] <table class="wikitable sortable" style="text-align:center; font-size:90 ...
## [15] <table class="wikitable sortable" style="text-align:right style=">\n<cap ...
## [16] <table class="wikitable"><tbody>\n<tr>\n<th>Constituency\n</th>\n<th col ...
## [17] <table class="nowraplinks mw-collapsible autocollapse navbox-inner" styl ...
## [18] <table class="nowraplinks hlist mw-collapsible autocollapse navbox-inner ...
## [19] <table class="nowraplinks hlist mw-collapsible autocollapse navbox-inner ...
## [20] <table class="nowraplinks hlist mw-collapsible mw-collapsed navbox-inner ...
## ...
From the wiki page, we can pick out pick out a specific table. If we want to look at the “Results of the 2014 European Parliament election”, we can sift through our output from the previous code chunk and see that it is table 15.
We’ll use html_table() to get the tables and pipe in pluck() from the purr package to specify the table we’re looking for in our data. Because some of the cells in the table are empty, previously we would need to use fill=TRUE in html_table(). As of this writing, that argument is depreciated and the function now fills all missing cells automatically with ‘NA’. We’ll save the object as ep14_raw to indicate it is the raw, unchanged data. Then we’ll use class() to confirm we’ve saved the data as a data_frame.
ep14_raw <- data_table %>%
html_table(fill=TRUE) %>%
purrr::pluck(15)
class(ep14_raw)
## [1] "tbl_df" "tbl" "data.frame"
Now that we’ve extracted the data we want, we can begin to clean it.
We’ll start by looking at the last bit of data, anticipating it will need to be cleaned because of what we saw on the wikipage.
tail(ep14_raw)
## # A tibble: 6 × 10
## Party Party Votes Votes Votes Seats Seats Seats `` ``
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl> <lgl>
## 1 "" NI21 10,5… 0.1 "New" "0" "" "" NA NA
## 2 "" Peace Party 10,1… 0.1 "" "0" "" "" NA NA
## 3 "" Others 55,0… 0.3 "3.4" "0" "" "" NA NA
## 4 "Valid Votes" Valid Votes 16,4… 99.5 "" "73" "1" "" NA NA
## 5 "Rejected Votes" Rejected Vo… 90,8… 0.6 "" "" "" "" NA NA
## 6 "Overall turnout" Overall tur… 16,5… 35.6 "0.9" "" "" "" NA NA
We see that the last three rows are aggregated data that we don’t need, so we’ll remove those and then verify they are gone. We’ll also assign a new name for our cleaned dataframe indicating it is no longer the raw data.
ep14 <- ep14_raw[-c(32:34), ] # Specify the index numbers of the rows we want to remove from the data
tail(ep14)
## # A tibble: 6 × 10
## Party Party Votes Votes Votes Seats Seats Seats `` ``
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl> <lgl>
## 1 "" Yorkshire First 19,017 0.1 "New" 0 "" "" NA NA
## 2 "" Europeans Party 10,712 0.1 "New" 0 "" "" NA NA
## 3 "" Green (NI) 10,598 0.1 "" 0 "" "" NA NA
## 4 "" NI21 10,553 0.1 "New" 0 "" "" NA NA
## 5 "" Peace Party 10,130 0.1 "" 0 "" "" NA NA
## 6 "" Others 55,011 0.3 "3.4" 0 "" "" NA NA
Now we’ll move to the beginning of our data for cleaning.
head(ep14)
## # A tibble: 6 × 10
## Party Party Votes Votes Votes Seats Seats Seats `` ``
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl> <lgl>
## 1 "Party" Party Numb… % +/- Seats +/- % NA NA
## 2 "" UK Independence Party 4,37… 26.6 10.6 24 11 32.9 NA NA
## 3 "" Labour Party 4,02… 24.4 9.2 20 7 27.4 NA NA
## 4 "" Conservative Party 3,79… 23.1 3.8 19 7 26.0 NA NA
## 5 "" Green Party of Englan… 1,13… 6.9 0.9 3 1 4.1 NA NA
## 6 "" Liberal Democrats 1,08… 6.6 6.7 1 10 1.4 NA NA
We can see that the variable names are not unique, so we’ll give specific names to variables we are interested in, and innocuous names to the ones we aren’t. Then we’ll keep only those columns that we are interested in, and check our work.
names(ep14) <- c("V1", "party", "votes", "percent_share", "V5",
"seats", "V7", "V8", "V9", "V10") # Rename columns
ep14 <- ep14[, c("party", "votes", "percent_share", "seats")] # Keep only the columns we want
head(ep14)
## # A tibble: 6 × 4
## party votes percent_share seats
## <chr> <chr> <chr> <chr>
## 1 Party Number % Seats
## 2 UK Independence Party 4,376,635 26.6 24
## 3 Labour Party 4,020,646 24.4 20
## 4 Conservative Party 3,792,549 23.1 19
## 5 Green Party of England and Wales 1,136,670 6.9 3
## 6 Liberal Democrats 1,087,633 6.6 1
Then we’ll remove the first row which is just a duplicate of the column headers.
ep14 <- ep14[-c(1), ]
head(ep14)
## # A tibble: 6 × 4
## party votes percent_share seats
## <chr> <chr> <chr> <chr>
## 1 UK Independence Party 4,376,635 26.6 24
## 2 Labour Party 4,020,646 24.4 20
## 3 Conservative Party 3,792,549 23.1 19
## 4 Green Party of England and Wales 1,136,670 6.9 3
## 5 Liberal Democrats 1,087,633 6.6 1
## 6 Scottish National Party 389,503 2.4 2
Lastly, we’ll identify the numeric variables as such.
ep14 <- ep14 %>%
mutate(
votes = parse_number(votes), # removes commas from the votes column
percent_share = as.numeric(percent_share),
seats = as.numeric(seats)
)
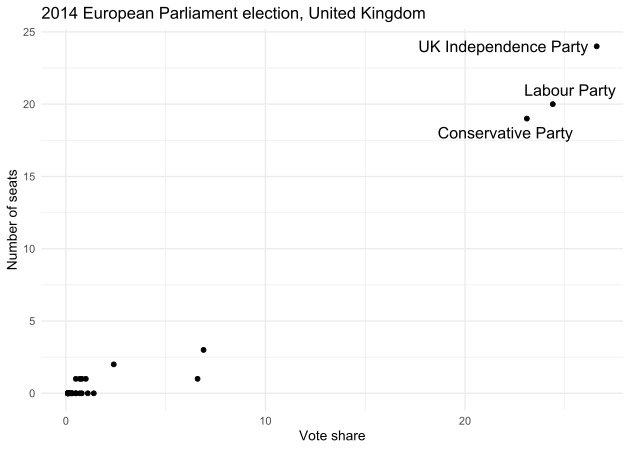
Now that we’ve created our data we’ll finish up our practice by creating a simple dot plot and add a label for the parties that have a vote share greater than 15%.
ggplot(ep14, aes(x = percent_share, y = seats)) +
geom_point() +
theme_minimal() +
ggrepel::geom_text_repel(
aes(label = ifelse(percent_share > 15, party, '')),
size = 4.5,
point.padding = .2,
box.padding = .4
) +
labs(
y = "Number of seats",
x = "Vote share",
title = "2014 European Parliament election, United Kingdom"
)